1 - Introduction to the Cluster
The cluster, with domain name mlkd.tp.vps.inesc-id.pt, comprises 9 virtual machines. Namely:
- 7 dedicated to computation
douro,lima,mondego,sado,tamega,tejo,zezere
- 1 to host the group's website and monitor GPU usage on other machines
mlkd
- 1 for centralized authentication and file sharing within the cluster
atlantico
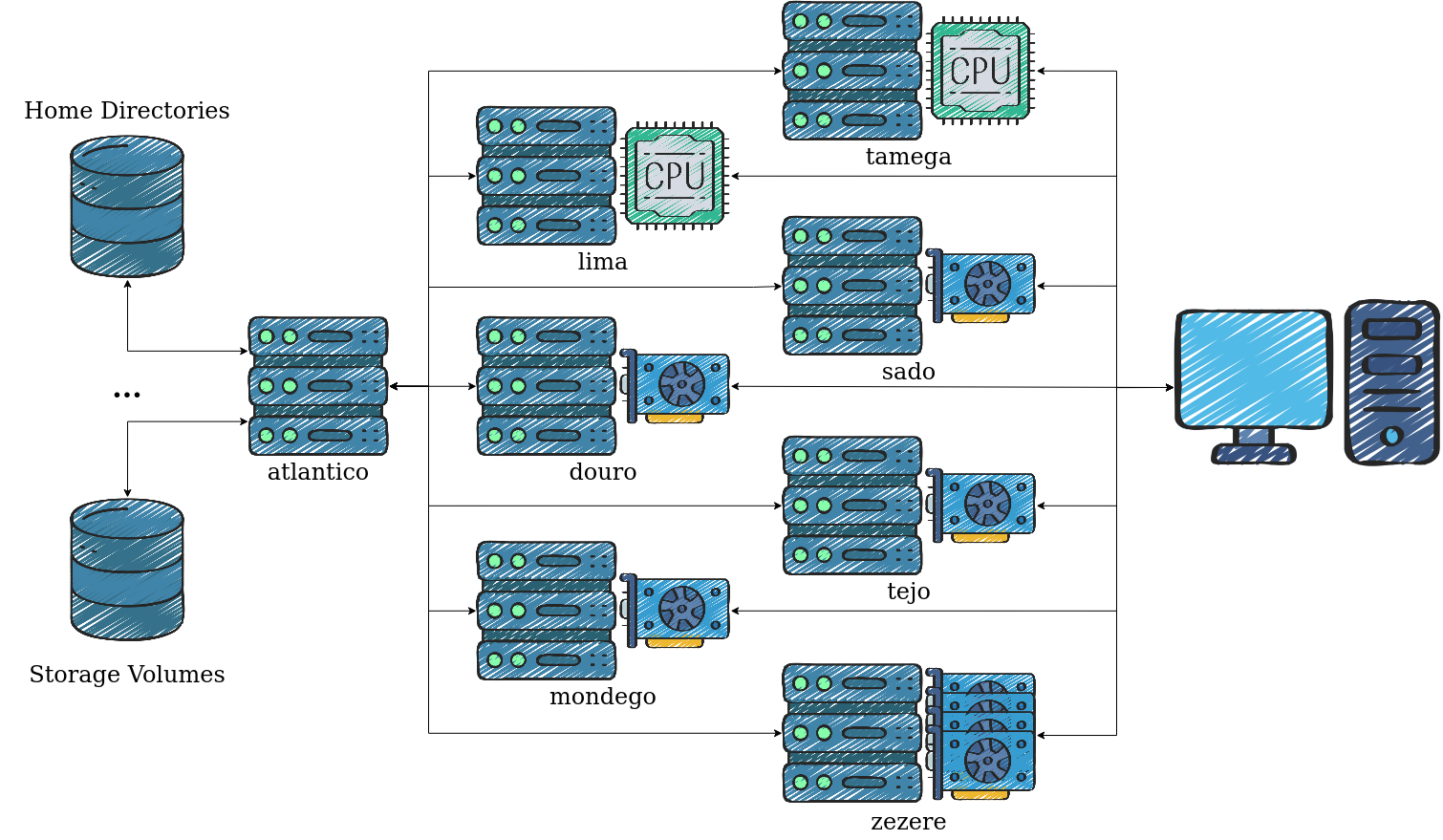
For simplicity, in this guide, the machines will be referred to only by their hostname. E.g., tejo.mlkd.tp.vps.inesc-id.pt will be referred to by tejo.
1.1 - Authentication and File Server
The cluster's centralized authentication service is provided by atlantico. Whenever you log into a machine, it's with atlantico they communicate to authenticate you. This centralization allows easier account creation and management. However, it also constitutes a Single Point of Failure (SPoF), since a failure by atlantico leads all machines to become unavailable.
Additionally, atlantico provides a Network File System (NFS), that allows seamless access to the same files in all machines, avoiding data replication and ensuring environment consistency. However, this solution makes atlantico a SPoF for data access, and reduces data access speed, since it becomes constrained by network speed rather than memory and bus speed.
1.1.1 - Home Directories
Home directories are stored in a single disk, attached to atlantico, which exports them to all other machines via NFS.
To prevent abusive usage, they are limited by a usage quota (currently 15GB). If you exceed this quota, you will get an error message finishing with Disk quota exceeded. If this happens:
- Delete unnecessary files or move them to your local machine
- If you are still exceeding the quota, contact the cluster administrator
1.1.2 - Data Storage
Datasets, especially large ones, are usually stored in separate disks. Additionally, some users might have disks to store personal data that does not fit in their home directory. These disks are attached to atlantico and exported via NFS to each machine's /media directory.
Currently, the following public datasets are available:
- Flickr30 (opens in a new tab)
- ImageNet 1k (opens in a new tab)
- Metadataset (opens in a new tab)
- MS COCO (opens in a new tab)
If you need to store a dataset that does not fit in your home directory, either public or private, contact the cluster administrator.
1.1.3 - IO Intensive Operations
The cluster's NFS solution has several advantages. However, it also leads to some issues. Since files are shared over the network, each transfer consumes network bandwidth. Therefore, IO intensive operations can lead to:
- Network congestion
- High latency
- Slow data transfer rates
- Decreased overall system performance
There is no single solution for this problem, but the following might help:
- Load the full dataset from disk to RAM at the start of the program, instead of loading items on the fly, i.e., on the Dataset's
__init__method rather than on__getitem__ - Store your data in formats optimized for compression, such as, HDF5 (opens in a new tab), TFRecord (opens in a new tab), LMDB (opens in a new tab), Parquet (opens in a new tab)
- Ask the cluster administrator to mount your disk directly on the machine running your code
1.2 - Computation Machines
Currently, machines dedicated to compuation have 5 types of configuration:
- 96 cores CPU, 960GB RAM, 4x80GB NVIDIA A100 GPUs
guadiana
- 40 cores CPU, 256GB RAM, 4x32GB NVIDIA V100 GPUs
zezere
- 48 cores CPU, 240GB RAM, 2x48GB NVIDIA A40 GPUs
cavado,vouga
- 8 cores CPU, 64GB RAM, 32GB NVIDIA V100 GPU
douro,mondego,sado,tejo
- 44 cores CPU, 120GB RAM, no GPU
lima,tamega
Except for sado and guadiana, you can use any machine, according to your needs. As a rule of thumb, you can consider the following:
- You only need CPU
lima,tamega
- You need a single GPU
douro,mondego,tejo
- You need more than a single GPU or all other machines are busy
cavado,vouga,zezere
When using machines with multiple GPUs, you should only split your model between multiple GPUs if you really need to. Otherwise, you should use a single GPU and should avoid using one that is already in use. Additionally, to maximize resource usage efficiency, when using a GPU, you should always aim to use as much GPU memory as possible.
Unlike other machines, cavado and vouga have 2.4TB ephemeral disks, which are much faster to access than other disks, and can be used to store input data for model training. However, keep in mind that, as the name suggests, these disks are ephemeral, and anyone can read from and write on them. Thus, they shouldn't be used to store private data or data for which you don't have other copies.
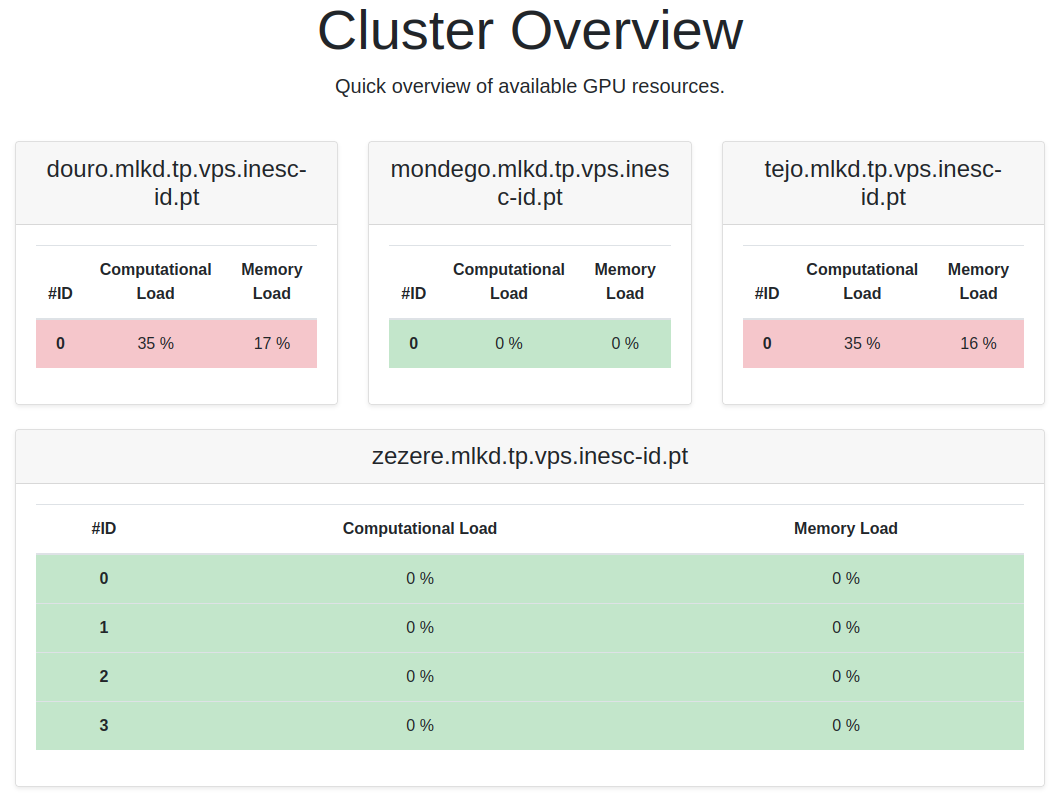
1.3 - GPU Monitor
To determine the machine where you can run your code without having to access them all, you can use the GPU Monitoring Service (opens in a new tab).